Overview
PyCaret is an open-source, low-code machine learning library in Python that aims to reduce the cycle time from hypothesis to insights. It is well suited for seasoned data scientists who want to increase the productivity of their ML experiments by using PyCaret in their workflows or for citizen data scientists and those new to data science with little or no background in coding. PyCaret allows you to go from preparing your data to deploying your model within seconds using your choice of notebook environment. Please choose your track below to continue learning more about PyCaret.
link:- https://pycaret.org/

Table of Contents
- What is PyCaret and Why Should you Use it?
- Installing PyCaret
- Problem statement and Dataset
- Training Machine Learning Model using PyCaret
- Analyze Model
What is PyCaret and Why Should you Use it?
PyCaret is an open-source, machine learning library in Python that helps you from data preparation to model deployment. It is easy to use and you can do almost every data science project task with just one line of code.
I have found PyCaret useful. Here are two reasons why:
- PyCaret being a low-code library makes you more productive. With less time spent coding, you and your team can now focus on business problems.
- PyCaret is simple and easy to use machine learning library that will help you to perform end-to-end ML experiments with fewer lines of code.
Installing PyCaret

Problem statement and Dataset
In this article, we are going to solve a classification problem. We have a breast cancer dataset with features like radius_mean, area_mean, texture_mean, diagnosis whether patients have Malignant or Benign cancer. We will build a machine learning model that will help doctors to identify the cancers malignant or benign.
The dataset has 569 rows and 31 columns. You can find the complete code and dataset used in this
Let’s start by reading the dataset using the Pandas library:
import pandas as pd
path = "https://raw.githubusercontent.com/alamjane/Project/master/Breast%20Cancer.csv"
df = pd.read_csv(path)
df.head()
Initializing the Setup: In this step, PyCaret performs some basic preprocessing tasks, like ignoring the ID, imputing the missing values, encoding the categorical variables, and splitting the dataset into the train-test split for the rest of the modeling steps. When you run the setup function, it will first confirm the data types, and then if you press enter, it will create the environment for you to go-ahead
# Importing module and initializing setup
from pycaret.classification import *
clf1 = setup(data = df, target = 'diagnosis')
Training Machine Learning Model using PyCaret
Training a model in PyCaret is very simple. You need to use the create_models function that takes just the one parameter
compare_models()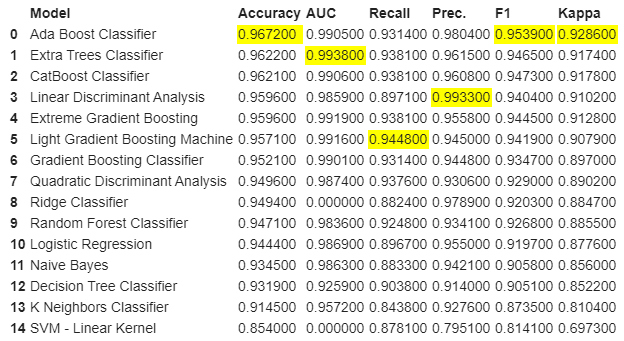
Here Ada Boost Classifier has better accuracy than other algorithms. For training the Ada Boost model, you just need to pass the string “ada”:
ada = create_model('ada')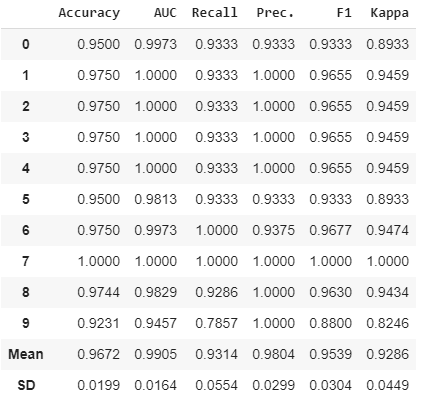
Hyperparameter tuning
We can tune the hyperparameters of a machine learning model by just using the tune_model function which takes one parameter — the model abbreviation string (the same as we used in the create_model function).
Let’s tune it.
tuned_ada = tune_model('ada')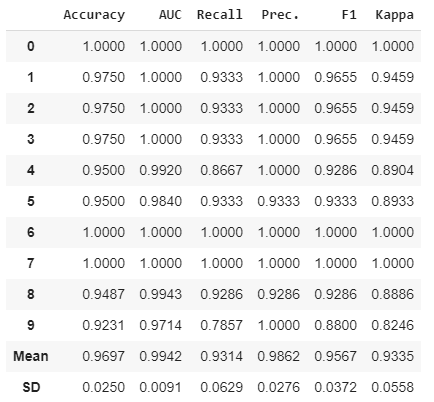
Analyze Model
Now, after training the model, the next step is to analyze the results. Analyzing a model in PyCaret is again very simple. Just a single line of code and you can do
Plot Model Results
You can plot model results by providing the model object as the parameter and the type of plot you want. Let’s plot the AUC-ROC curve and decision boundary:
AUC Curve
plot_model(estimator = tuned_ada, plot = 'auc')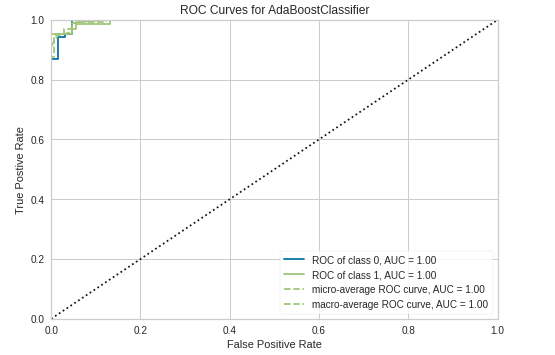
Learning Curve for Ada Boost Classifier
plot_model(estimator = tuned_ada, plot = 'learning')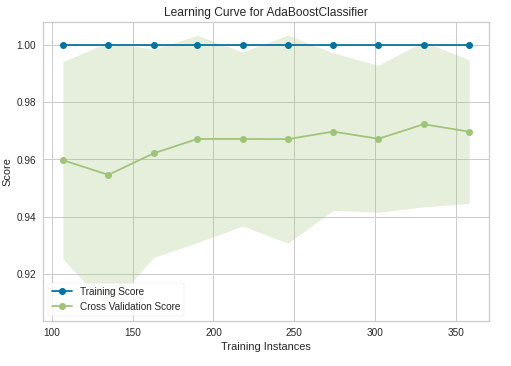
Confusion Matrix
plot_model(estimator = tuned_ada, plot = 'confusion_matrix')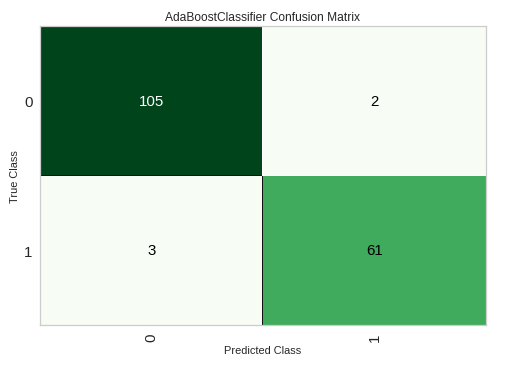
Conclusion
It really is that easy to use. I’ve personally found PyCaret to be quite useful for generating quick results.
Practice using it on different types of datasets — you’ll truly get more interest and it will help.
If you have any suggestions/feedback related to the article, please post them in the comments section below. I look forward to hearing about your experience using PyCaret as well.
